
Deep learning has revolutionised computer vision. Today, there are not many problems where the best performing solution is not based on an end-to-end deep learning model. In particular, convolutional neural networks are popular as they tend to work fairly well out of the box. However, these models are largely big black-boxes. There are a lot of things we don’t understand about them.
Despite this, we are getting some very exciting results with deep learning. Remarkably, researchers are able to claim a lot of low-hanging fruit with some data and 20 lines of code using a basic deep learning API. While these results are benchmark-breaking, I think they are often naive and missing a principled understanding.
In this blog post I am going to argue that people often apply deep learning models naively to computer vision problems – and that we can do better. I think a really good example is with some of my own work from the first year of my PhD. PoseNet was an algorithm I developed for learning camera pose with deep learning. This problem has been studied for decades in computer vision, and has some really nice surrounding theory. However, as a naive first year graduate student, I applied a deep learning model to learn the problem end-to-end and obtained some nice results. Although, I completely ignored the theory of this problem. At the end of the post I will describe some recent follow on work which looks at this problem from a more theoretical, geometry based approach which vastly improves performance.
I think we’re running out of low-hanging fruit, or problems we can solve with a simple high-level deep learning API. Specifically, I think many of the next advances in computer vision with deep learning will come from insights to geometry.
What do I mean by geometry?
In computer vision, geometry describes the structure and shape of the world. Specifically, it concerns measures such as depth, volume, shape, pose, disparity, motion or optical flow.
The dominant reason why I believe geometry is important in vision models is that it defines the structure of the world, and we understand this structure (e.g. from the many prominent textbooks). Consequently, there are a lot of complex relationships, such as depth and motion, which do not need to be learned from scratch with deep learning. By building architectures which use this knowledge, we can ground them in reality and simplify the learning problem. Some examples at the end of this blog show how we can use geometry to improve the performance of deep learning architectures.
The alternative paradigm is using semantic representations. Semantic representations use a language to describe relationships in the world. For example, we might describe an object as a ‘cat’ or a ‘dog’. But, I think geometry has two attractive characteristics over semantics:
-
Geometry can be directly observed. We see the world’s geometry directly using vision. At the most basic level, we can observe motion and depth directly from a video by following corresponding pixels between frames. Some other interesting examples include observing shape from shading or depth from stereo disparity. In contrast, semantic representations are often proprietary to a human language, with labels corresponding to a limited set of nouns, which can’t be directly observed.
-
Geometry is based on continuous quantities. For example, we can measure depth in metres or disparity in pixels. In contrast, semantic representations are largely discretised quantities or binary labels.
Why are these properties important? One reason is that they are particularly useful for unsupervised learning.
Unsupervised learning
Unsupervised learning is an exciting area in artificial intelligence research which is about learning representation and structure without labeled data. It is particularly exciting, because getting large amounts of labeled training data is difficult and expensive. Unsupervised learning offers a far more scalable framework.
We can use the two properties which I described above to form unsupervised learning models with geometry: observability and continuous representation.
For example, one of my favourite papers last year showed how to use geometry to learn depth with unsupervised training. I think this is a great example of how geometric theory and the properties described above can be combined to form an unsupervised learning model. Other research papers have also demonstrated similar ideas which use geometry for unsupervised learning from motion.
Aren’t semantics enough?
Semantics often steal a lot of the attention in computer vision – many highly-cited breakthroughs are from image classification or semantic segmentation.
One problem with relying just on semantics to design a representation of the world, is that semantics are defined by humans. It is essential for an AI system to understand semantics to form an interface with humanity. However, because semantics are defined by humans, it is also likely that these representations aren’t optimal. Learning directly from the observed geometry in the world might be more natural.
It is also understood that low level geometry is what we use to learn to see as infant humans. According to the American Optometric Association, we spend the first 9 months of our lives learning to coordinate our eyes to focus and perceive depth, colour and geometry. It is not until 12 months when we learn how to recognise objects and semantics. This illustrates that a grounding in geometry is important to learn the basics in human vision. I think we would do well to take these insights into our computer vision models.

Examples of geometry in my recent research
I’d like to conclude this blog post by giving two concrete examples of how we can use geometry in deep learning from my own research:
Learning to relocalise with PoseNet
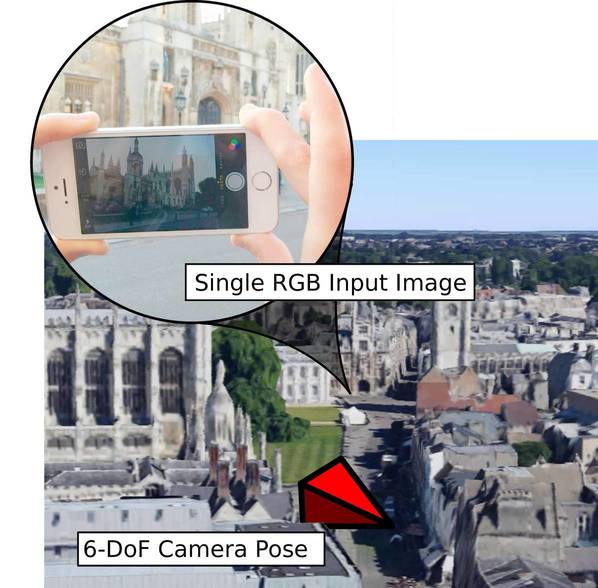
In the introduction to this blog post I gave the example of PoseNet which is a monocular 6-DOF relocalisation algorithm. It solves what is known as the kidnapped robot problem.
In the initial paper from ICCV 2015, we solved this by learning an end-to-end mapping from input image to 6-DOF camera pose. This naively treats the problem as a black box. At CVPR this year, we are going to presenting an update to this method which considers the geometry of the problem. In particular, rather than learning camera position and orientation values as separate regression targets, we learn them together using the geometric reprojection error. This accounts for the geometry of the world and gives significantly improved results.
Predicting depth with stereo vision
The second example is in stereo vision – estimating depth from binocular vision. I had the chance to work on this problem while spending a fantastic summer with Skydio, working on the most advanced drones in the world.
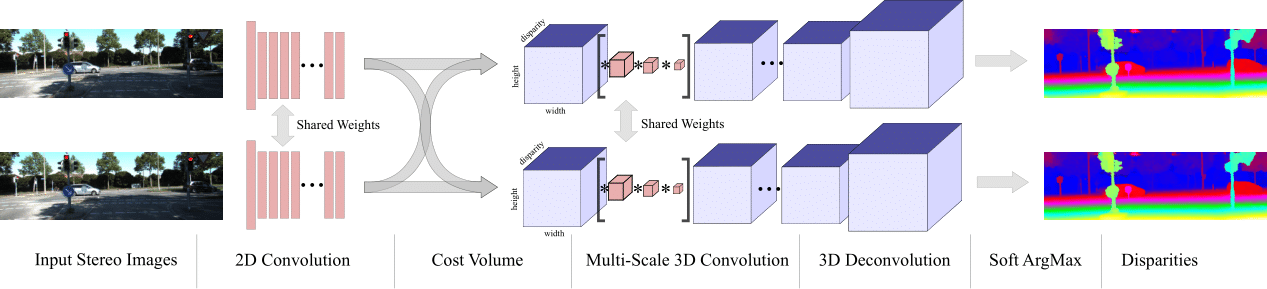
Stereo algorithms typically estimate the difference in the horizontal position of an object between a rectified pair of stereo images. This is known as disparity, which is inversely proportional to the scene depth at the corresponding pixel location. So, essentially it can be reduced to a matching problem - find the correspondences between objects in your left and right image and you can compute depth.
The top performing algorithms in stereo predominantly use deep learning, but only for building features for matching. The matching and regularisation steps required to produce depth estimates are largely still done by hand.
We proposed the architecture GC-Net which instead looks at the problem’s fundamental geometry. It is well known in stereo that we can estimate disparity by forming a cost volume across the 1-D disparity line. The novelty in this paper was showing how to formulate the geometry of the cost volume in a differentiable way as a regression model. More details can be found in the paper here.
Conclusions
I think the key messages to take away from this post are:
- it is worth understanding classical approaches to computer vision problems (especially if you come from a machine learning or data science background),
- learning complicated representations with deep learning is easier and more effective if the architecture can be structured to leverage the geometric properties of the problem.
Leave a Comment